Theory
Mutual Information (MI)
I have used MI in projects involving co-evolving amino acids in proteins and seizure detection in EEG data. In some cases, MI performs well (like with EEG data), while in others, it’s less effective (as with proteins). For proteins, I estimated that MI might need another billion years of evolution to fully capture the complexities! However, when it comes to word analysis in wine reviews, MI works exceptionally well for feature selection.
"A Bag of Words, a Binary Matrix and MI"
When calculating MI for a multiple sequence alignment of proteins, each amino acid residue is placed in a column, represented by its residue number. I applied a similar approach to text by splitting the words in a review, letting each unique word represent a column. Then, I calculated the MI between the review’s label (red or white) and each unique word. Words that share the most information with the labels are likely the best for classification or quantitative analysis. A Bag of Words can be defined in several ways, as it’s essentially a collection of unique words. It could represent all unique words across reviews or words specific to labeled groups of reviews. In my case, the dataset consists of 89,000+ reviews across 600+ wine varieties, with over 34,000 unique words in total. To reduce computational cost, I standardized the text and removed stop words. From there, I selected the 4,000 most common words to form the main Bag of Words. The Binary Matrix is initially defined by the words in this Bag of Words. Each review is then matched against this matrix, where the presence of a word is marked with a 1, and its absence with a 0, resulting in a “fingerprint” in the form of a binary vector. This matrix also standardizes the word content across all reviews and captures patterns or similarities between groups in the data. While using a binary matrix may strip some of the sentiment and nuance from the reviews, this abstraction can be essential for improving prediction accuracy, especially for non-standardized text like wine reviews.
Word Selection and Prediction
The number of words in the Bag of Words and the number of words extracted by MI impact the model’s predictability. Wine reviews are subjective and vary greatly in length, content, and the number of words related to characteristics like quality or color. My model bases its predictions on the content of many reviews but only utilizes a fraction of all available words. Red and white wines are often characterized by specific words. In my color model, words with the highest MI related to the wine’s label color (red or white) are extracted from the Bag of Words. Many of these words are typical descriptors of red and white wines. Instead of relying on a predefined corpus, I use MI to dynamically select the key reference words that populate the binary matrix for the prediction model.
Typical Features (words) extracted using MI:
Some of the words selected with MI for building the model can be tested by submitting the example words from the table of wine color descriptors. I didn’t manage to capture them all, though!
The image below describe a binary matrix with animals as column names, a short text and typical labels.

In this example you can classify all the animal labels, after dropping the dog, hen and elk. The dog don't provide any mutual information, and the elk and hen provide very little MI.
Unsupervised / Supervised Machine Learning
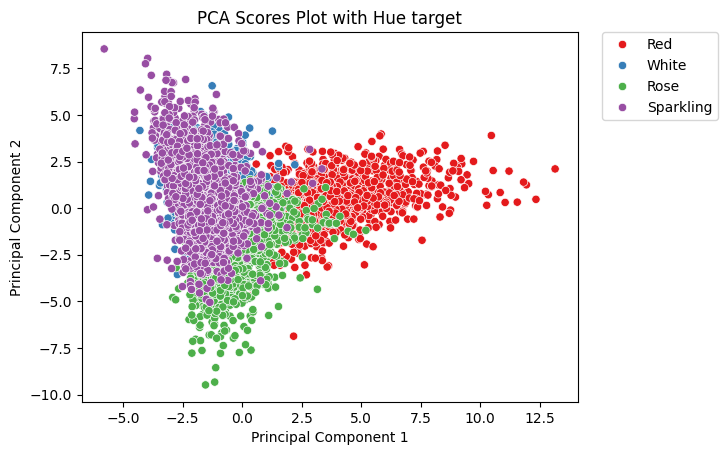
“It might seem like a crazy combination, but it works! To check if the binary matrix contains information about wine color, we can use an unsupervised method like Principal Component Analysis (PCA) to visualize potential clusters by coloring a scatter plot based on the score values and wine labels. Interestingly, the first principal components only explain a small portion of the variance—typically between 1 and 3 percent. Yet, despite this low explained variance, there’s still a clear tendency for the data to form clusters. This happens because Mutual Information (MI) is a non-parametric method that captures relationships based on probability distributions, without making assumptions about the data. PCA, on the other hand, explains variation by identifying linear, orthogonal principal components. So while PCA focuses on overall linear variance, MI is able to pick up more complex patterns that PCA might miss.”
Predicting wine quality based on quality scores given in reviews.
With wine reviews being a human experience of a wine tasting, I could not get a better Pearson rank coefficient higher than 0.8 with different models. The error of the predicted results will vary over the range and reflect that a quality score for a wine is related to a human experience and not a standardized measure.
Predicting the variety
Predicting the variety, such as if a wine is Red, White, Rosé or Sparkling is doable. The only issue is that White, Rosé and Sparkling wines share many descriptors. In the color model I set Rosé to be predicted as Red for now. I built a model with logistic regression that predicts the variety and it struggle with White and Sparkling as they are close when it comes to descriptors. One issue is also that I had to scale down the dataset and can only use 6400 reviews while the color model used 50000 reviews. The lack of reviews for Rosé was the reason to scale down. To balance the smaller dataset I also tailored the Bag of Words by randomly selecting 1600 reviews and picking the top 2000 words for each class. As the Bag of Words contain unique words it only contained roughly 3700 words. To make sure each class contributed with a fairly equal amount of words I calculated how many words they contributed with, and also how many words that was shared between the classes. The API gives two predictions one based on the neural network modell for color and one prediction of variety based on the logistic regression method.
Model Performance
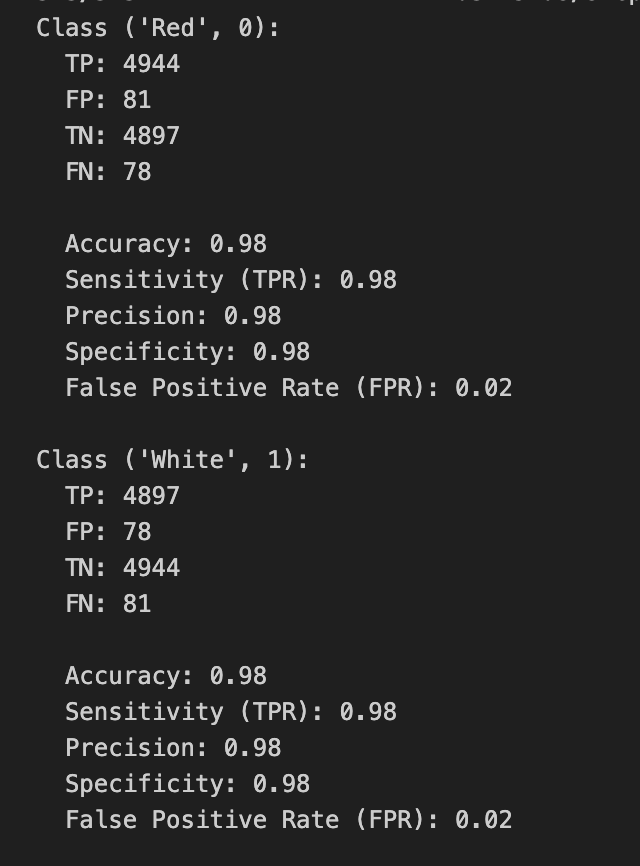
Color Prediction
25000 reviews x 2 classes (Red & White)
Rosé is labelled as Red and Sparkling as White.
The main bag of words was set to 4000 of the most common words from all reviews.
n MI words = 500
PCA performed on the Bag of Words and MI-Words Binary Matrices with the label used as Color for the PCA scores show that information that discriminate between color is present in the binary matrix.
| PCA Bag of Words | PCA MI-Words |
|---|---|
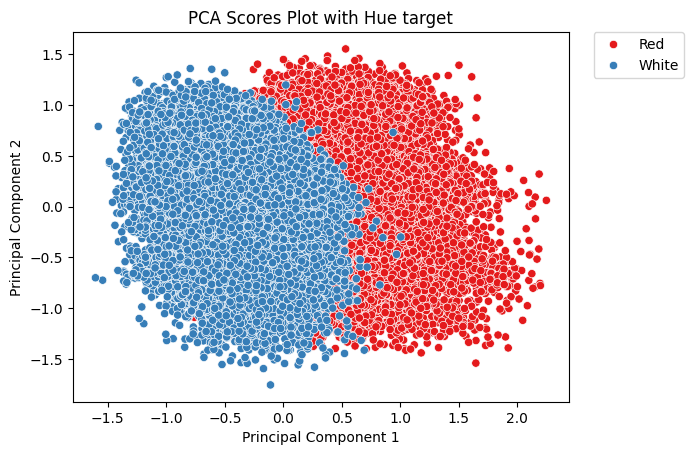
|
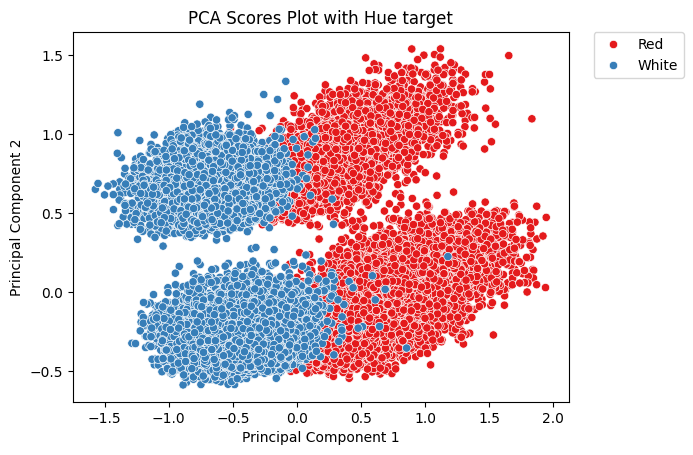
|
ANN Model
The model is a sequential model with only 1 hidden layer with two neurons, and a output layer with two neurons.
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=(input_dim,)),
tf.keras.layers.Dense(2, activation='relu'),
tf.keras.layers.Dense(2, activation='sigmoid')
])
Only 2-3 epochs is necessary to get a high accuracy and sensitivity. I built a logistic regression model that had similar performance as this ANN-model.
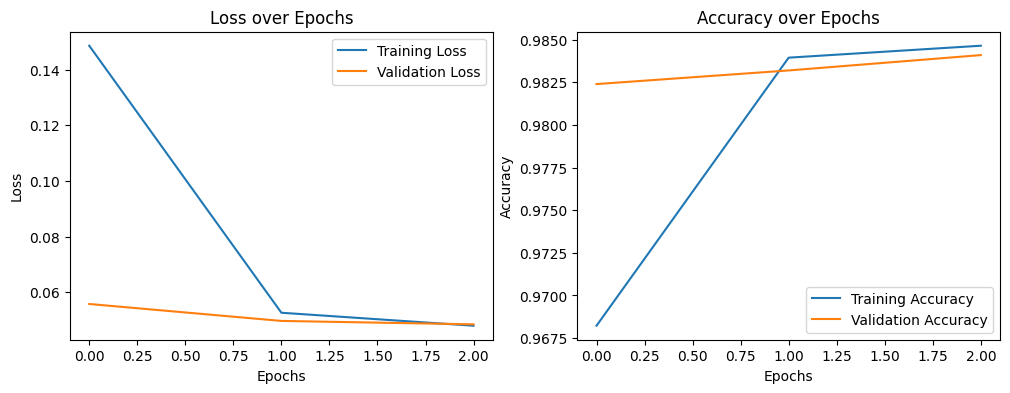
|
|
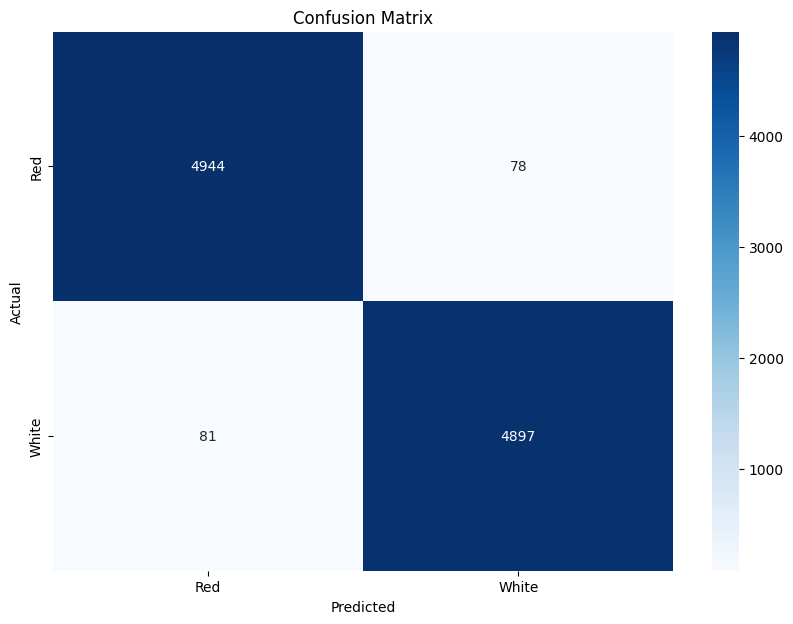
|
|
Classification of wine varieties
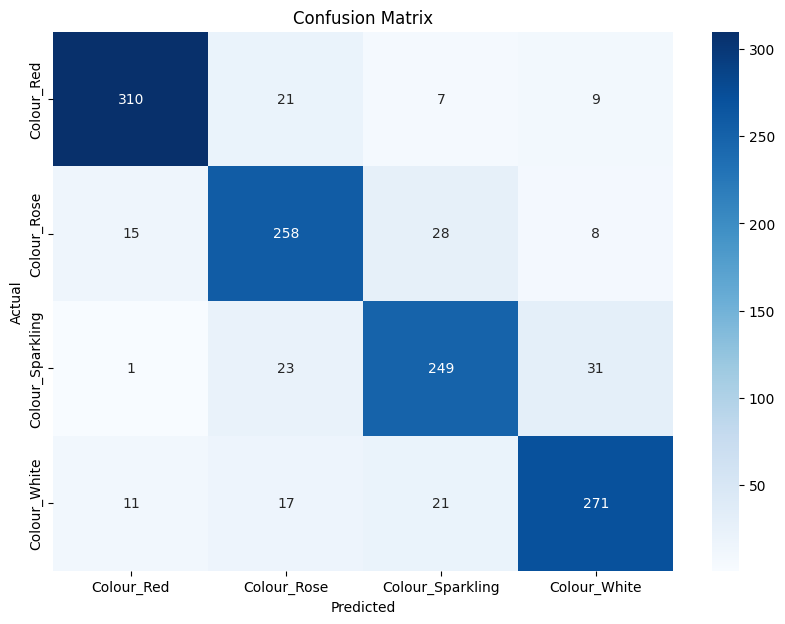
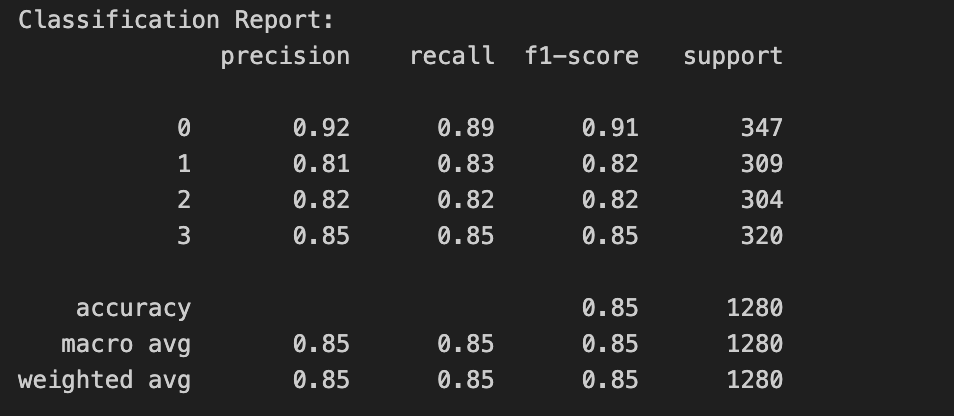
All four classes include words that do not help distinguish between them, as well as some that overlap across classes. To determine if a binary matrix could reliably predict wine variety in a balanced model, the number of shared words was assessed, revealing that 877 words are common to all four classes. Additionally, some column names in the raw data conflicted with the binary matrix structure and were removed for compatibility.
The four classes share a balanced number of words when considering mutual information (MI) terms, highlighting why it’s challenging to distinguish between Rosé, White, and Sparkling wines based on their shared vocabulary. While these Bags of Words are derived from thousands of reviews, an individual review may lack enough unique terms for accurate classification. Mutual information identifies the words that contribute the most information for each class, which includes terms commonly shared across all classes.
Since each class Bag of Words is based on the frequency of words used to describe that class, and this model was calibrated to the class with the fewest reviews (Rosé), the randomly selected reviews for Sparkling, White, and Red wines may not be ideal for optimal model performance. The number of words chosen for each class also influences the overall Bag of Words. For example, if the word limit is set to 1,000 per class, the main Bag of Words will contain around 1,700 words. Nevertheless, using mutual information (MI) combined with a binary matrix approach demonstrates that effective text classification is achievable, yielding strong results.
In the table below the amount of shared words between the various bags of words are shown.
| PCA | Sample Selection |
|---|---|
|
1600 reviews x 4 classes 2000 words from each class Bag of Words = 3667 n MI words = 500 |
| Words Shared | |
|---|---|
| With Bag of Words | Between Classes |
|
|
Logistic Regression Variety Prediction
| Confusion Matrix | Overall Prediction Statistics |
|---|---|
|
|
The number of "MI" words impact on the prediction accuracy
"Too few words will not cover enough variance, while too many words will introduce noise"
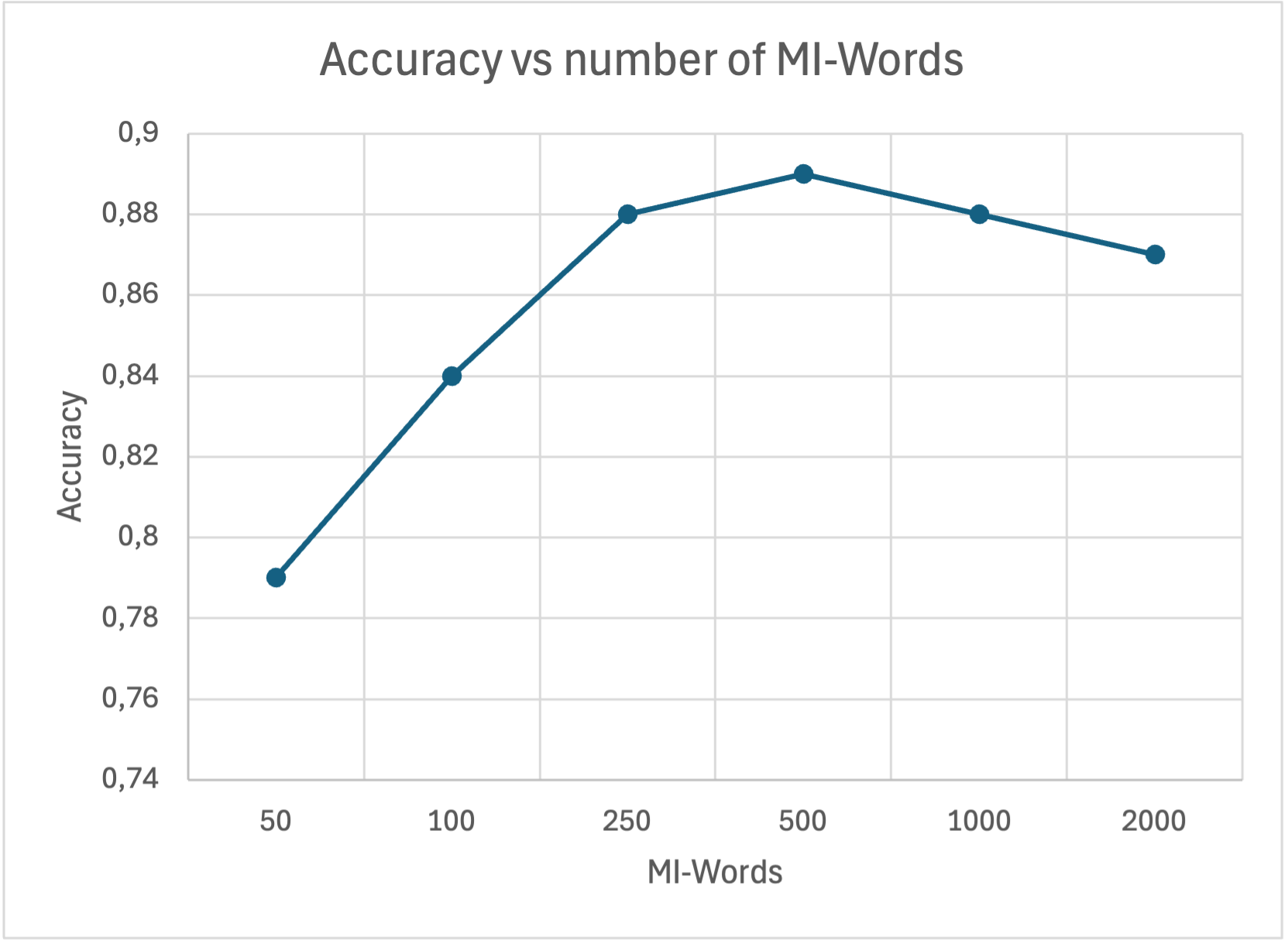
|
|

|
XGBoost and ANN multiple class predictions
Both XGBoost and a ANN model perform comparable with logistic regression.
| CM: XGBoost 500 MI-words | Classification Report: XGBoost 500 MI-words |
|---|---|
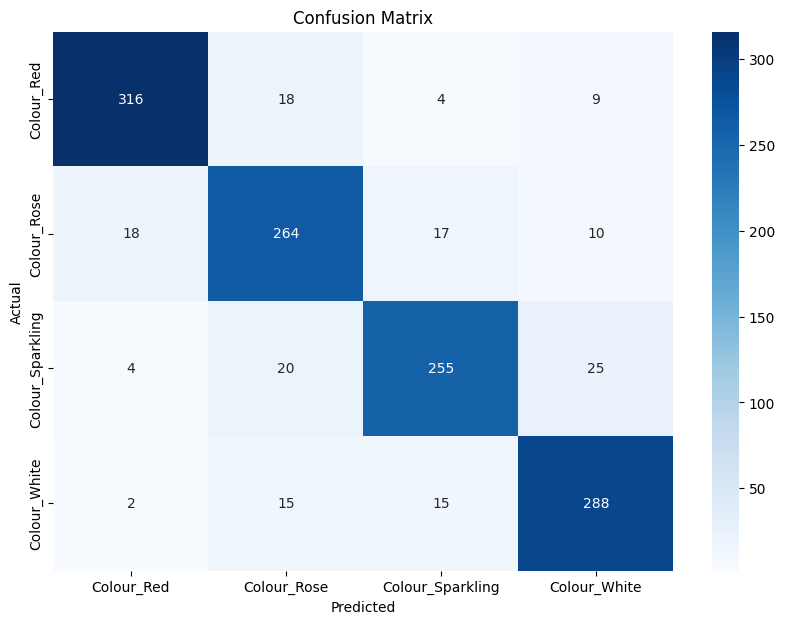
|
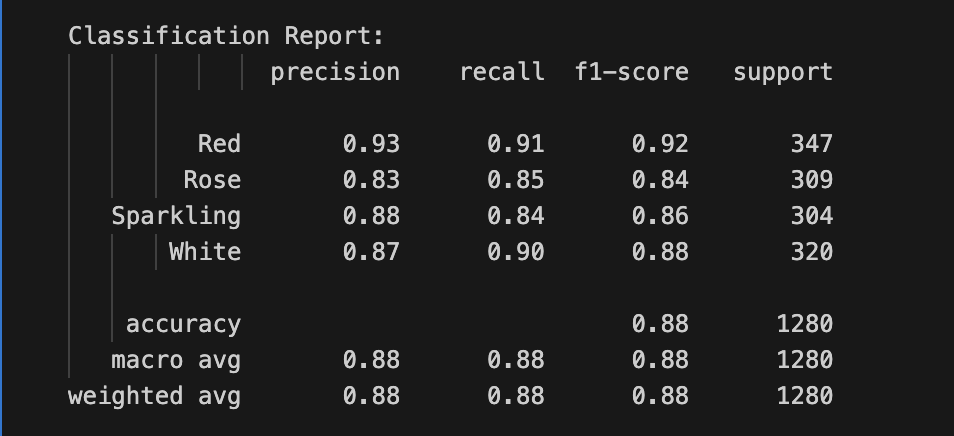
|
ANN Model Layout:

ANN Training:

I decided to only use 4 epochs to avoid possible overfitting, but I did not fully explore the optimal parameters or consider using early stopping. The fact that XGBoost and Logistic Regression perform as good as a ANN makes it easier to choose a logistic regression model for simple deployment.
| CM: ANN 500 MI-words | Prediction: ANN 500 MI-words | |
|---|---|---|
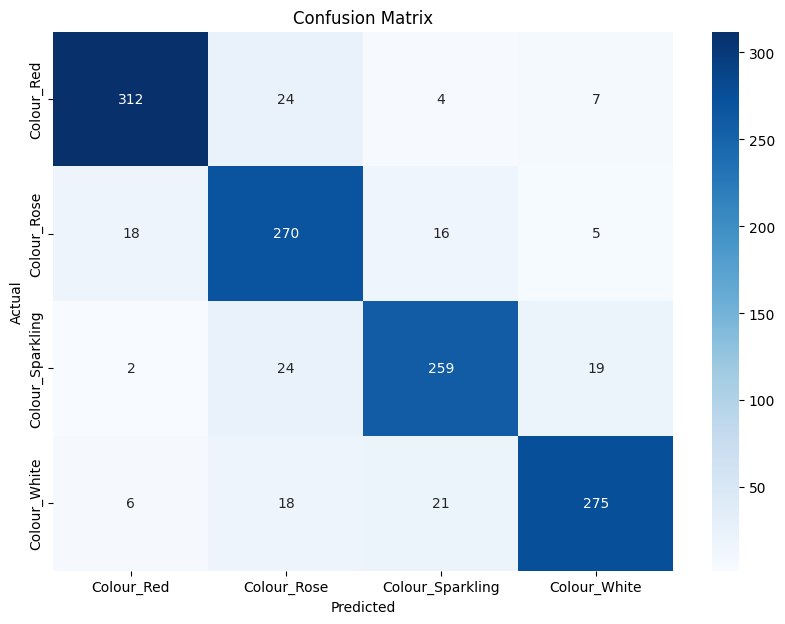
|

|

|
Convolutional Neural Networks (CNN) and Text
I decided to build a model that uses binary vectors, unique for the four classes Red, White, Sparkling and Rosé. For each of these classes the most common 20 words were selected with MI. Then I selected the 20 most common words for each class and the combination of classes. The selection was based on presence using their labels. All words were then combined into a Bag of words, and a sample matrix with unique words as columns. Each sample in the training and validation data then consist of a binary matrix, that can be regarded as a black and white image suitable for input into a CNN. The total number of words in the Bag of words was 52. The CNN struggled with classyfying 4 classes but performed very well if sparkling was excluded and only 3 classes, thus 4800 reviews were used. 20 words for the 3 classes gave a union bag of words that contained 37 unique words. With a recall in the range from 0.81 to 0.93. This indicate the power of using a CNN which uses less words to achieve as good predictions as models based on ANN, logistic regression and XGBoost.
| Confusion Matrix 4 classes | Confusion Matrix 3 classes |
|---|---|
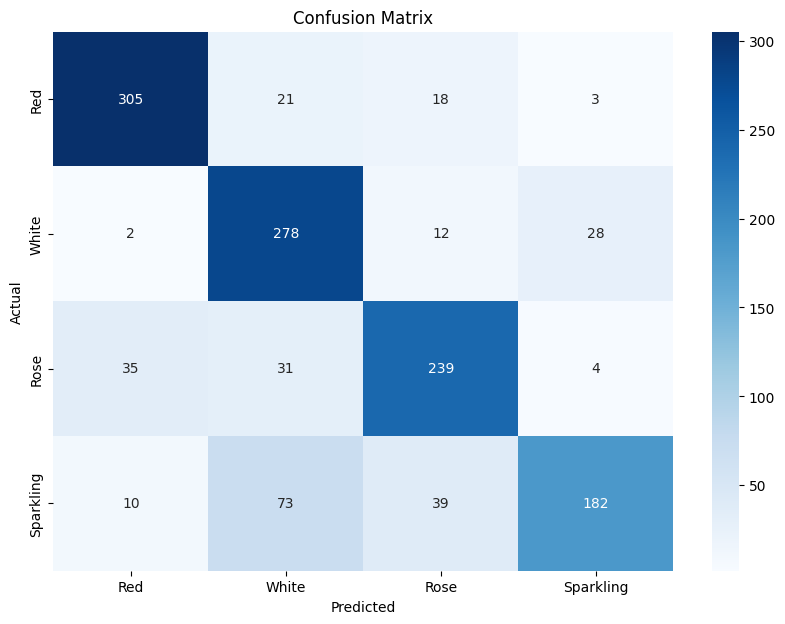
|
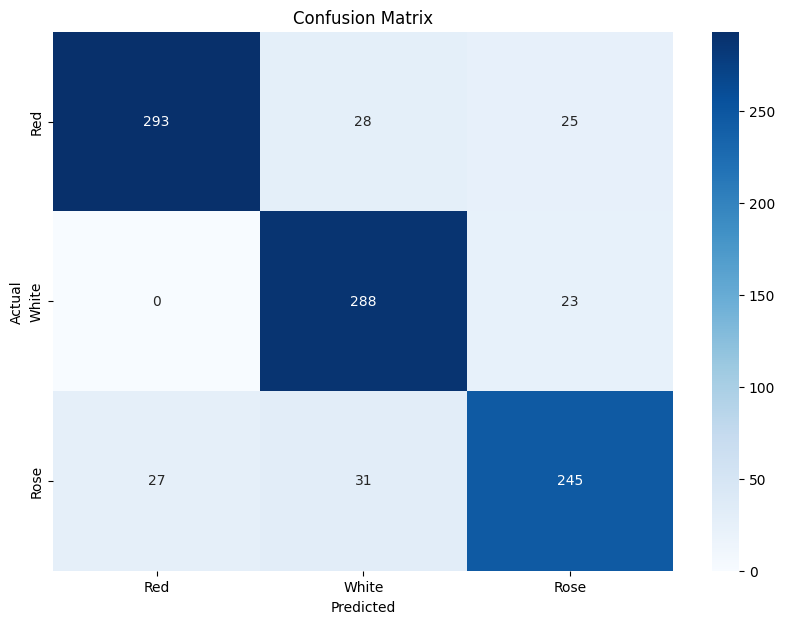
|
| Prediction Results 3 Classes | A Graphic representation of the class binary matrix |
|---|---|
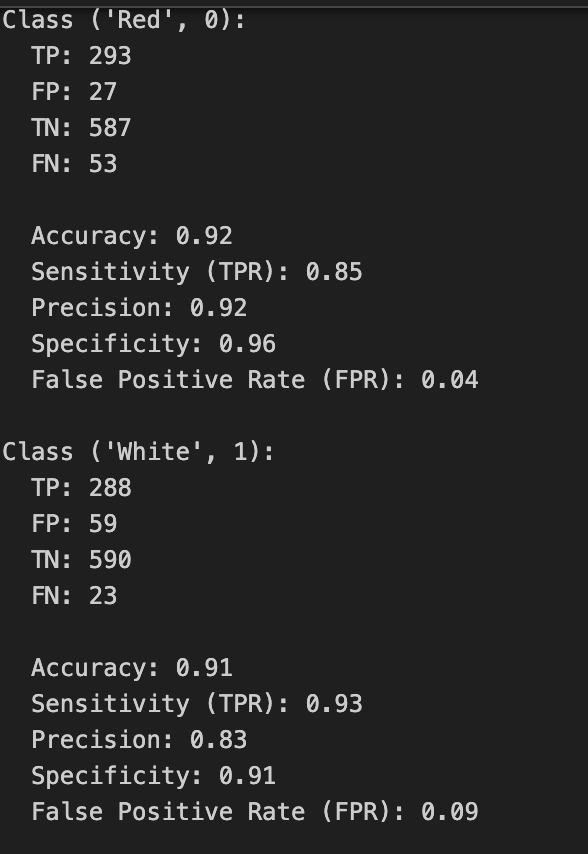
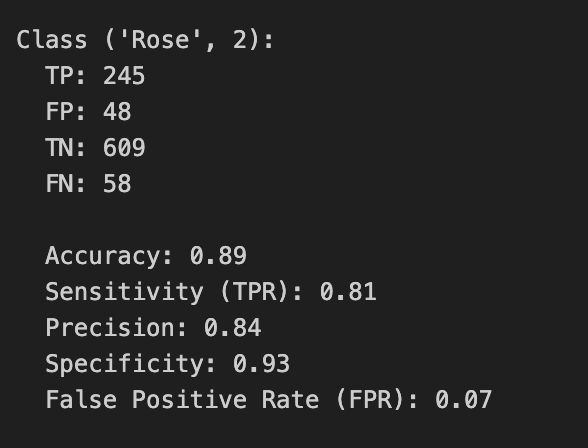
|
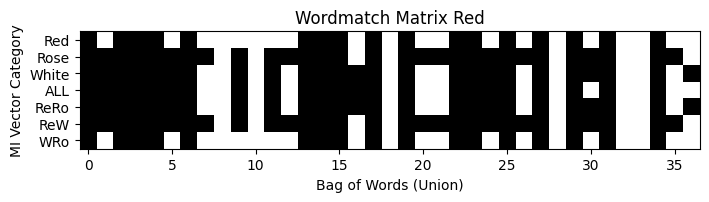
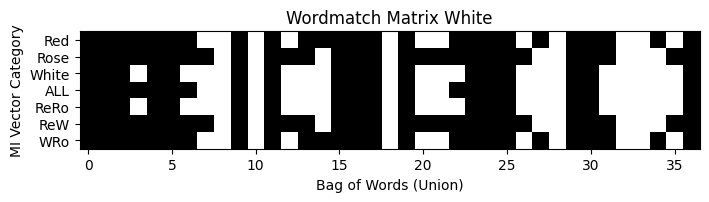

|
GPT-2 Embeddings
I used the word embeddings derived with the basic GPT-2 community model from huggingface and sent the output into a sequential ANN model with 3 hidden layers, to determine how good it could predict wine classes. The model still need work on the architecture as it clearly shows underfitting. The GPT-2 model most likely benefit from fine tuning with wine review text.
| Underfitting | Overall Prediction Statistics |
|---|---|
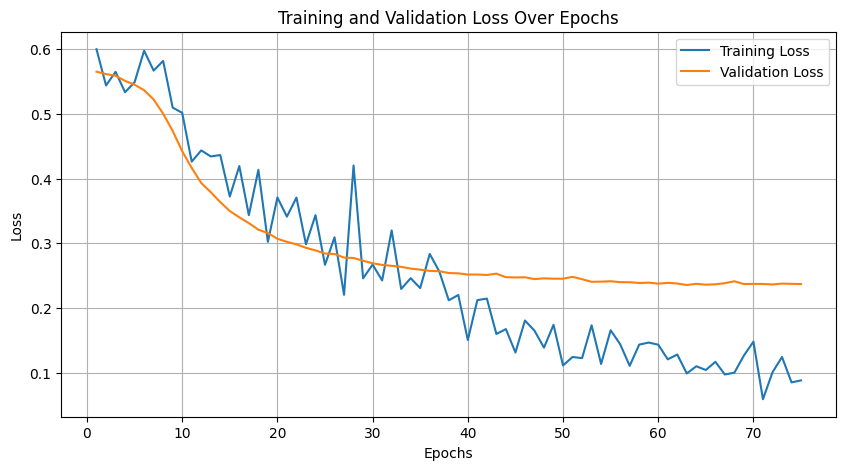
|
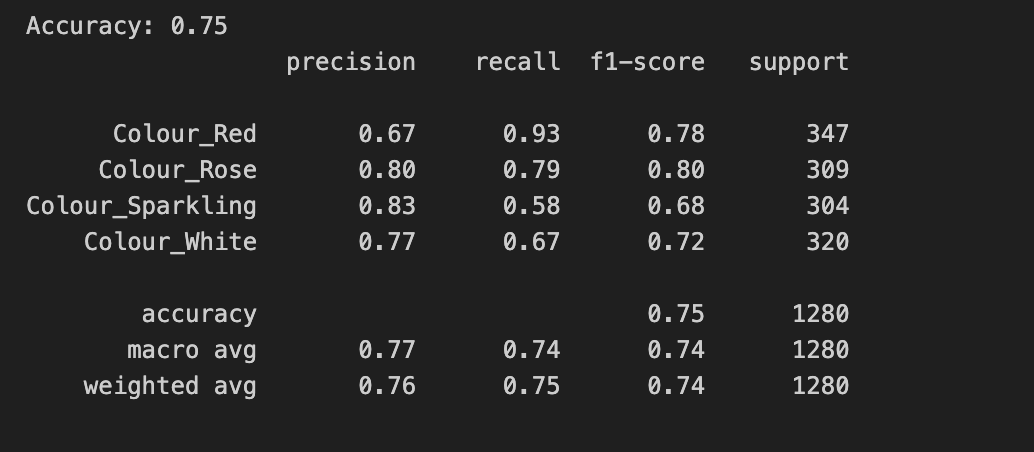
|
Is This Useful?
I aimed to evaluate the information contained in wine reviews to determine if qualitative classifications and predictions could be derived from the text. My approach involved using a straightforward method to convert text into numerical data. Comparing different “Bag of Words” representations—measuring the sums of unique, shared, and combined words—proved effective for constructing sample matrices. Additionally, using a binary matrix and mutual information (MI) for word extraction worked well for both cases. Understanding the potential for simple and efficient information extraction from text can be highly beneficial across fields, as it reduces computational costs and model complexity.